If you ask ChatGPT, Perplexity, Claude, and Google AI the same question, the lists of websites they cite as sources barely overlap. In 2026, only 11% of domains are cited by both ChatGPT and Perplexity for the same query. That number, from an analysis of 680 million citations, is the cleanest summary of where AI search is heading. Each engine has its own taste in sources, its own retrieval pipeline, and its own idea of what counts as authority.
For small business sites and solo founders, this changes the optimization problem. A page that wins in Google AI Overviews may be invisible in ChatGPT. A page Perplexity cites every week may never surface in Claude. The work splits into platform-specific patterns, and the patterns are now well documented.
This article was prompted by a Reddit comment. In r/SEO_for_AI a marketer pushed back on the assumption that AI SEO is just classical SEO with new terminology. The pushback hit the right nerve, and once I started digging into the published 2026 data and running my own tests, the divergence between engines turned out to be even more striking than the comment suggested. This piece puts those numbers and observations in one place.
TL;DR (Quick Summary)
Only 11% of domains are cited by both ChatGPT and Perplexity for the same query (Averi, 680M citation analysis, March 2026). A separate Passionfruit study of 15,000 queries found 12% overlap across three platforms.
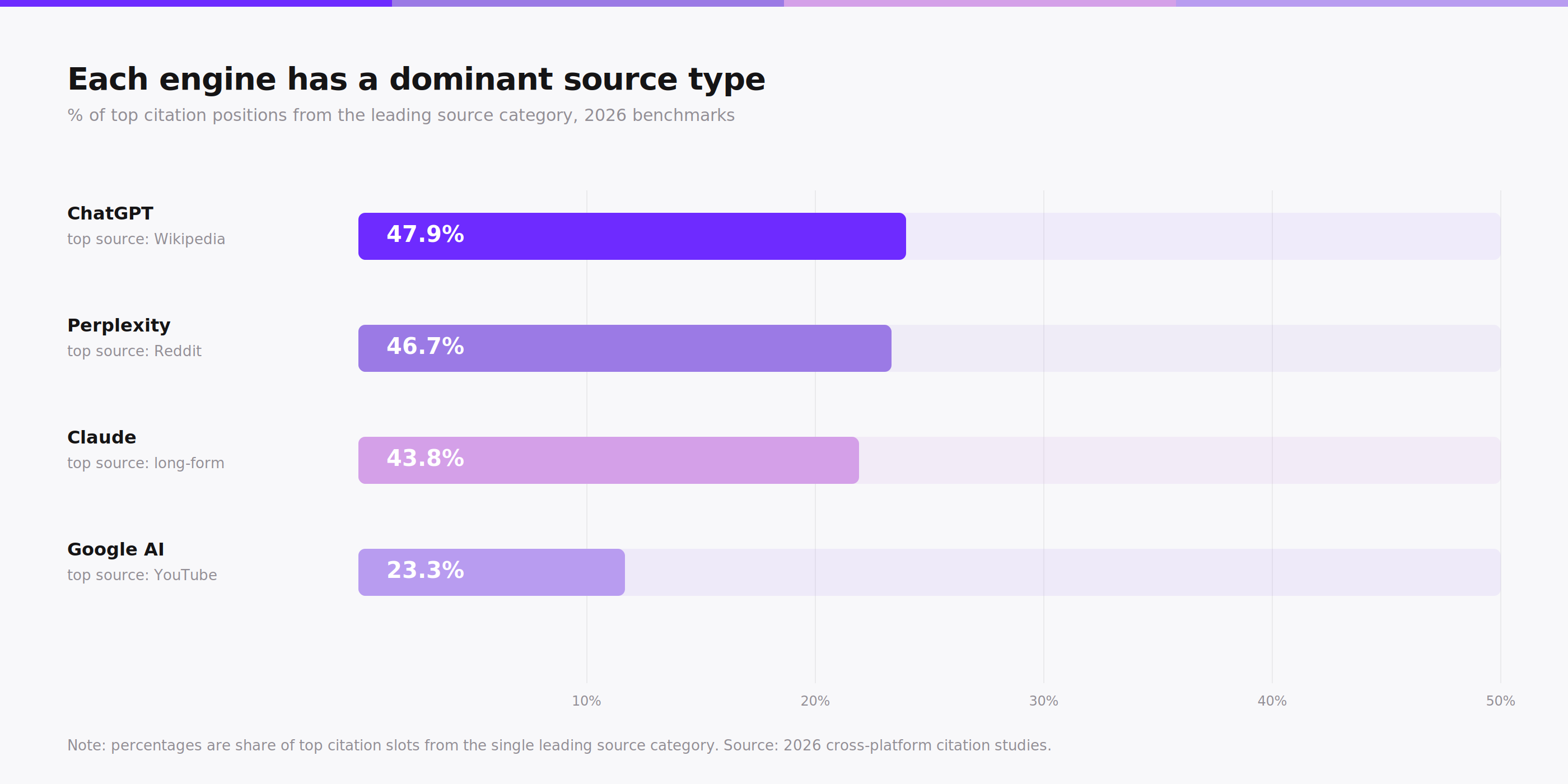
ChatGPT leans on Wikipedia (47.9% of top citations). Perplexity leans on Reddit (46.7%). Google AI Overviews pull heavily from YouTube (23.3%) and Reddit (21%). Claude favors long-form blogs and articles (43.8%).
88% of Google AI Mode citations do not come from Google's top 10 organic results (Moz, 2026). Classical ranking is no longer a reliable predictor of AI visibility.
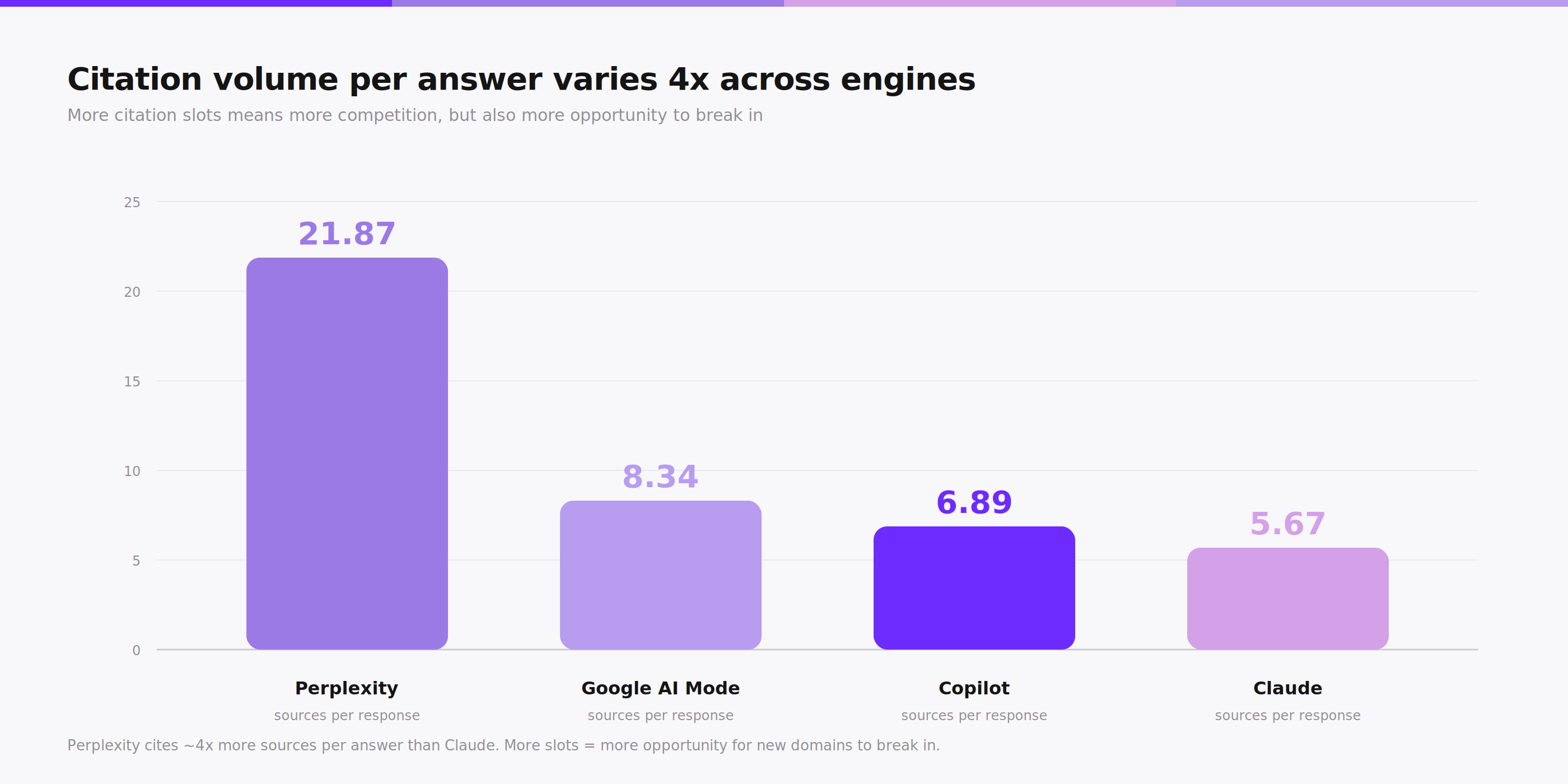
Citation volume per response varies sharply: Perplexity averages 21.87 sources, Google AI Mode 8.34, Copilot 6.89, Claude 5.67.
Perplexity is the most freshness-sensitive engine: 82% of its citations come from content under 30 days old.
Conversion rates favor AI traffic across the board: Claude 16.8%, ChatGPT 14.2%, Perplexity 12.4%, against Google organic at 2.8%.
The practical implication: optimize for each engine on its own terms. One playbook for all four no longer works.
How much do AI engines actually overlap?
Short answer: about 11% of domains are cited by both ChatGPT and Perplexity for the same query, and the figure is similar across other pairings.
The number comes from Averi's March 2026 analysis of 680 million citations across ChatGPT, Google AI Overviews, and Perplexity. Passionfruit's independent study of 15,000 queries found 12% source overlap across three platforms. Superlines' cross-platform analysis documented citation volume variance of up to 615x for the same brand between platforms. These are different methodologies arriving at the same conclusion: the engines do not cite the same sources, and the gap is large.
Each engine has a different dominant source category. Source: 2026 cross-platform citation studies.
Live test, May 2026
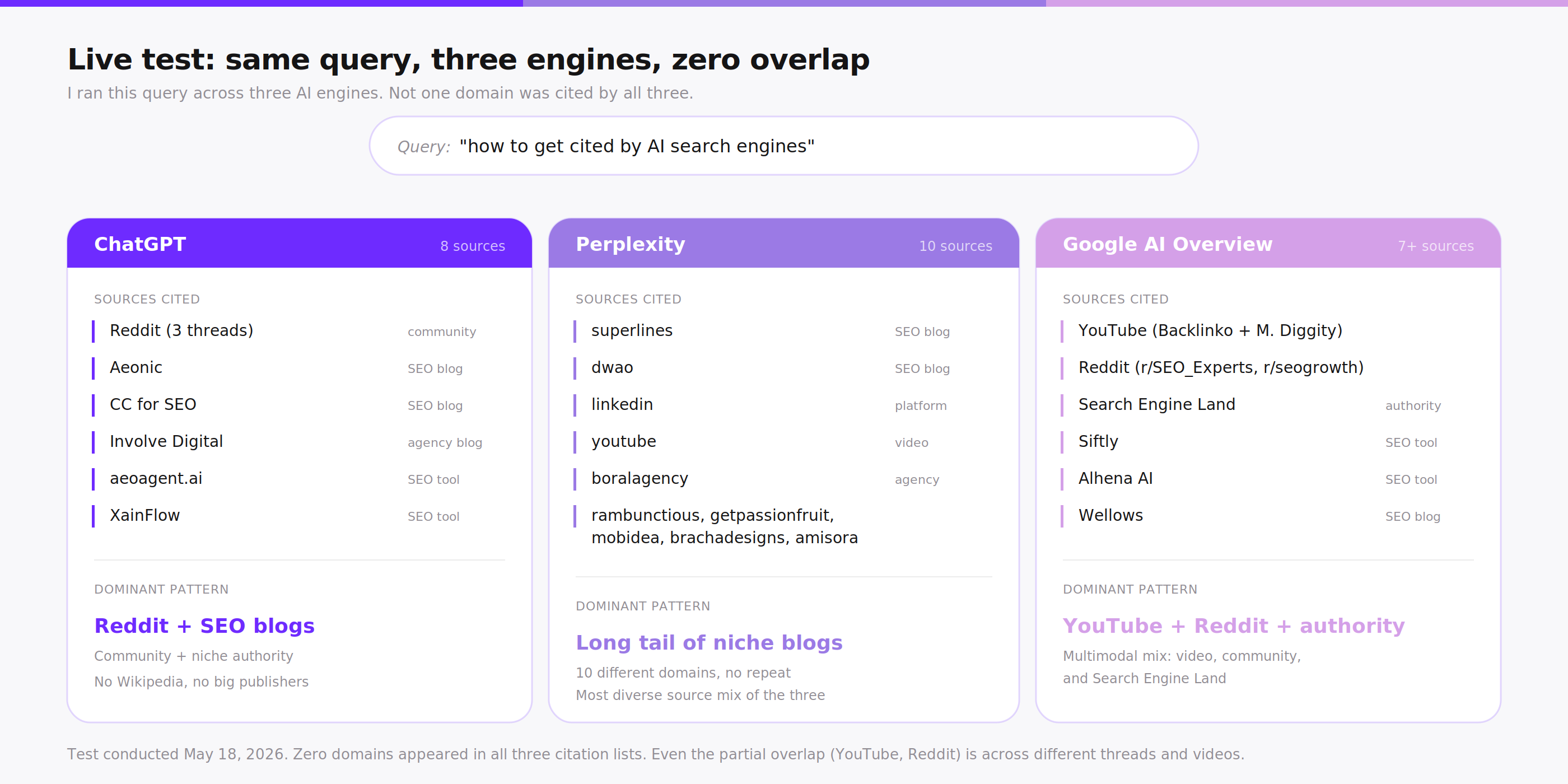
The numbers in the studies above are aggregates from millions of citations. To check whether the same pattern shows up in a real, current query, I ran "how to get cited by AI search engines" across ChatGPT (with web search), Perplexity, and Google AI Overview on the same day. Total unique domains cited: 23. Domains cited by all three engines: zero. ChatGPT pulled 3 Reddit threads plus 5 SEO blogs. Perplexity returned a long tail of 10 different niche blogs with no overlap among them. Google AI Overview pulled 2 YouTube videos (Backlinko, Matt Diggity), 2 Reddit threads, Search Engine Land, and a few SEO tools.
Live test, May 18 2026. 23 unique domains across three engines, zero domains in common.
Two different methods, same conclusion. The published reports analyze hundreds of millions of citations and find roughly 11% domain overlap. My single live test on a niche query produced 0% overlap. The aggregate number and the live observation converge on the same idea: different AI engines pull from different source pools, and treating them as one channel is the wrong mental model.
The raw screenshots from each engine are below, so you can see exactly what each returned:
Perplexity returned 10 sources. Long tail of niche SEO blogs and platforms.ChatGPT returned 8 sources, including 3 different Reddit threads and 5 SEO blogs.Google AI Overview pulled YouTube videos (Backlinko, Matt Diggity), Reddit threads, and Search Engine Land.
The implication is uncomfortable for anyone running a single AI-visibility strategy. If a brand measures its citation rate in ChatGPT and assumes the number applies elsewhere, roughly 89% of the citation landscape is invisible. ChatGPT was consistently the worst of the four for brand visibility across every B2B SaaS company tracked in a Slate HQ study of 300,000+ citations. Claude gave brands the highest owned-citation share at 9.1%. Perplexity gave them 6.8%. The per-platform profiles were so different they looked like different brands.
The engines also produce different volumes of citations per answer. Perplexity averages about 21.87 sources per response, Google AI Mode 8.34, Copilot 6.89, and Claude 5.67. More slots means more competition, but it also means more opportunity. A page that does not make the top 5 of a ChatGPT answer may still land in the top 20 of a Perplexity answer.
The right mental model is not "AI search" as a single channel. It is four channels with shared infrastructure and distinct editorial taste.
Treating AI visibility as a single number is like measuring your Google ranking and assuming it applies to Bing.
Where does ChatGPT get its information?
Short answer: ChatGPT pulls live web results through Bing's index when it has search access, and falls back on its training data when it does not. Its top external source is Wikipedia, cited in roughly 47.9% of top citation slots.
ChatGPT runs two different retrieval paths depending on the query. For real-time questions, it uses Bing as the underlying search index, then layers GPT on top to synthesize the answer. For general questions that do not require recency, it answers from training data, which is a fixed snapshot. This is why ChatGPT sometimes cites the open web and sometimes does not. If you have wondered whether ChatGPT gets information from the internet, the honest answer is: sometimes, depending on what you asked.
When ChatGPT does cite the web, its source mix is heavily tilted toward authoritative reference sites. Wikipedia leads the list at about 47.9% of top citation positions in 2026 benchmarks. The bias is structural. ChatGPT prefers sources that are stable, well-structured, and widely linked, because those signals match what large language models were trained to treat as reliable. Wikipedia checks every box.
Beyond Wikipedia, ChatGPT leans on industry publications, software review platforms like G2, and curated lists. It cites Reddit much less than Perplexity does, especially after a September 2025 source rebalancing that reduced Reddit's share to under 10% of ChatGPT citations. ChatGPT also has the lowest brand-visibility share of the four major engines in 2026 cross-platform studies, meaning it is harder to surface a specific brand here than in Claude or Perplexity.
On the question of whether ChatGPT cites Wikipedia: yes, consistently, and often as the primary source for definitional and historical questions. If you want to be the source ChatGPT pulls instead of Wikipedia, you need a page that is genuinely more comprehensive on a narrower topic than the Wikipedia entry.
One nuance worth noting: how ChatGPT chooses its sources depends on the model variant. The default model and the premium models can return different citation sets for the same prompt, because they have different retrieval pipelines under the hood. Anyone benchmarking ChatGPT citations should specify which model they tested.
Where does Perplexity get its information?
Short answer: Perplexity uses a hybrid index combining its own crawler with Bing, retrieves in real time on every query, and cites Reddit in about 46.7% of its top citation positions.
Perplexity is the most aggressive of the four engines on real-time retrieval. Every query triggers a fresh web search, and the engine averages about 21.87 citations per response, which is roughly three times what Claude or Copilot produce. The volume itself is part of the strategy. Perplexity tries to behave like a research assistant, surfacing many sources so the user can verify claims, rather than a chat bot that answers from memory.
Perplexity returns roughly 4x more sources per answer than Claude. More slots, more opportunity for new domains.
The source preferences are distinctive. Reddit accounts for 46.7% of Perplexity's top citations in 2026 benchmarks, by far the highest among major engines. Yes, Perplexity uses Reddit, and uses it heavily. Community forums, Q&A threads, and user-generated discussions feed Perplexity at a rate ChatGPT and Claude do not match. If a query has an experiential or opinion-driven dimension ("best X for small business"), Perplexity will almost certainly pull a Reddit thread into its answer.
Freshness is the other defining factor. About 82% of Perplexity citations come from content published or updated within the last 30 days. The engine actively prefers recent sources, including visible date signals like "2026" in the title or URL. Content older than a year competes at a structural disadvantage even when it is more authoritative.
A note on Reddit
Reddit being Perplexity's top source is not just a curiosity for optimization. For small business owners and marketers, Reddit is also a strong place to actually read. Subreddits like r/SEO, r/SEO_for_AI, r/SmallBusiness, and r/marketing host real conversations about what is working right now, often months before the trends show up in published research. The article you are reading exists because of a Reddit comment that pushed back on a common SEO assumption. Reddit rewards reading more than posting, and the engines that cite it are reflecting where useful information lives.
Perplexity also gives brands a comparatively high citation share. In one 2026 study of 300,000 citations across six B2B brands, Perplexity gave brands an owned-citation rate of 6.8%, higher than ChatGPT but lower than Claude. Combined with the highest volume of citations per response, Perplexity offers the most opportunity for new domains to break in.
Where does Claude get its information?
Short answer: Claude retrieves web content through Brave Search when it needs current information, and its top external source category is long-form blogs and articles, which account for about 43.8% of its citations.
Claude is built by Anthropic and uses Brave Search as its real-time retrieval layer. This is the simplest factual answer to where Claude gets its information: from Anthropic's training data for general knowledge, and from Brave-indexed pages for current questions. The Brave dependency matters because Brave's index differs from Google's and Bing's, which is one reason Claude cites different sources than ChatGPT or Google AI for the same query.
The source preferences lean toward depth. Long-form blogs, in-depth articles, and analytical pieces account for roughly 43.8% of Claude's citations. The engine seems to reward sources that explain rather than just announce, which is consistent with how Anthropic has positioned Claude for thoughtful answers rather than headline summaries. A 500-word news brief is less likely to be cited by Claude than a 3000-word explainer on the same topic.
Citation volume is on the lower end, at about 5.67 sources per response. Claude is more selective than Perplexity by a factor of nearly four. This means each individual citation carries more weight, and competition for those slots is higher per source.
Brand visibility on Claude is the highest of the four engines studied. In the same 300,000-citation cross-platform analysis, Claude gave brands an owned-citation share of 9.1%, the top of the field. Pair this with the highest conversion rate observed across AI traffic (Claude users convert at about 16.8%) and the engine becomes disproportionately valuable per visitor, even though raw traffic volumes are smaller than ChatGPT or Google AI.
Where does Claude AI get its information for niche or technical queries? Often from documentation pages, technical blogs, and primary sources rather than aggregators. If your content is a definitive guide on a specific topic, Claude is the engine most likely to surface it.
Where does Google AI Overview get its information?
Short answer: Google AI Overviews pull from Google's own index combined with the Knowledge Graph, and rely heavily on YouTube videos (23.3% of citations) and Reddit (21%).
Google AI Overviews and Google AI Mode both run on Google's proprietary index. They retrieve from the same underlying crawl that powers organic search, but with a different ranking and synthesis layer. This is why Google AI behaves differently from ChatGPT or Perplexity: the source pool is Google's full index, not Bing or Brave, and the retrieval logic uses Google's Knowledge Graph alongside the documents.
YouTube is the standout citation source, at about 23.3% of Google AI Overview citations. This is a multimodal preference: Google owns YouTube, indexes its transcripts, and weighs video content as a first-class citation candidate. A well-structured tutorial video can earn AI Overview citations that a text-only page on the same topic cannot. Reddit follows close behind at about 21%, with Quora at 14.3%, LinkedIn at 13%, and Wikipedia and Forbes around 5.7% each. For small business sites, this means creating one or two tutorial videos on core topics is a low-effort way to extend into Google AI surfaces.
The relationship between Google AI Overviews and Google's organic top-10 is more complex than people assume. About 38% of AI Overview citations come from pages in the top 10 organic results (Ahrefs data on 863,000 keywords and 4 million AI Overview URLs). That overlap is meaningful but partial. The other 62% comes from pages outside the top 10, often from authoritative niche sources that classical SEO would have buried. Our full guide to Google AI search optimization in 2026 goes deeper on how to engineer for both surfaces.
Google AI Mode, the standalone conversational interface, is more divergent. About 88% of AI Mode citations do not come from Google's organic top 10. The two surfaces (AI Overviews and AI Mode) share only 13.7% of cited URLs despite 86% semantic agreement on the answers themselves. The engines reach the same conclusions through different document paths.
The honest answer to where Google AI gets its information: Google's own index, with a strong preference for YouTube and Reddit, structured pages with schema markup, and content that contains direct answers in the first few hundred words. Pages updated within the last two months earn about 28% more AI citations than older content, so freshness matters here too, though less aggressively than on Perplexity.
Why each engine cites different sources
Short answer: each engine uses a different web index, a different retrieval pipeline, and a different idea of what counts as a trustworthy source. The differences are architectural, not random.
The first reason is the underlying search index. ChatGPT and Copilot both rely on Microsoft Bing. Perplexity blends its own crawler with Bing. Claude uses Brave Search. Google AI uses Google's index. Four engines, four different views of the web. Even when the same page exists on the web, the engines may not all have it crawled, indexed, or ranked the same way. The starting candidate pool is already different.
The second reason is the retrieval logic on top of the index. ChatGPT favors authoritative reference sources because its training rewarded that pattern. Perplexity favors community discussions and recent content because it was built as a research assistant for active investigation. Claude favors explanatory long-form because Anthropic tuned it for depth over speed. Google AI favors structured signals (schema markup, Knowledge Graph entities, YouTube transcripts) because Google has decades of infrastructure for those signals and few competitors do.
The third reason is the prompt itself. Every AI engine personalizes its retrieval to the framing of the question. The same intent worded differently can pull different sources from the same engine. Even within a single ChatGPT session, asking the same question twice can return slightly different citation sets because the model samples its retrieval candidates rather than picking deterministically.
The fourth reason is policy. Some engines have made deliberate editorial choices about source mix. ChatGPT reduced its Reddit share in September 2025 as part of a quality rebalancing. Perplexity has leaned harder into Reddit and forums over time. Google AI Overviews have shifted toward video as YouTube indexing has matured. These are not accidents of math, they are product decisions.
The cumulative effect: same query, four different answers, four different source lists. Treating them as one channel produces blind spots in three out of four.
Why Google rank no longer predicts AI citations
Short answer: about 88% of Google AI Mode citations do not come from the organic top 10, and ChatGPT shows only 6.5% URL overlap with Google's top results. Ranking #1 on Google does not mean you will be cited by AI.
The disconnect is documented across multiple independent studies. Moz analyzed 40,000 keywords in 2026 and found 88% of Google AI Mode citations did not come from the top 10 organic results. Ahrefs analyzed 863,000 keywords and 4 million AI Overview URLs and found the overlap between Google's top 10 and AI Overview citations dropped from 76% to 38% in six months. ChatGPT shows only 6.5% URL overlap with Google's top results, according to Semrush data.
Three independent studies, same direction. Ranking #1 on Google is not the lever it used to be.
The reason is that AI engines optimize for a different objective than search engines. A search engine ranks pages by relevance and authority for a query. An AI engine extracts specific facts from candidate pages and assembles them into a synthesized answer. A page can rank #1 on Google for being a comprehensive overview, but lose to a specific FAQ answer or a structured table on a lower-ranked page when the AI is looking for one extractable claim.
This does not mean traditional SEO is dead. Roughly 97% of AI Overview citations come from indexed content, so being crawlable and indexable is still load-bearing. Pages with First Contentful Paint under 0.4 seconds average 6.7 AI citations, while slower pages drop to 2.1. Schema markup increases citations by about 28%, and pages with original data get 4.1x more citations than aggregator pages. The fundamentals still matter. But the fundamentals are necessary, not sufficient.
What does predict AI citations better than Google rank? Brand mentions. Analysis of 7,000+ citations found brand search volume correlates with AI citation frequency at 0.334, stronger than backlink count. Sites with 32,000+ referring domains have 2x the citation rate on ChatGPT. The signal is breadth of independent mention across the web, not just ranking position on one query.
For small business sites, the practical takeaway is that earning a few citations across G2, industry publications, Reddit threads, and YouTube tutorials may move AI visibility faster than chasing one more ranking position on Google.
What to do for each engine
Each engine rewards a different optimization angle. The four steps below are the most direct levers per platform.
01
For ChatGPT: be Wikipedia-adjacent
ChatGPT prefers stable, authoritative, well-structured reference content. The path to citation is not "compete with Wikipedia" but "be the source Wikipedia would link to." That means publishing pages with clear definitions, citable statistics, named sources, and consistent terminology. Get listed in industry databases and review platforms like G2. Earn mentions in long-form publications that Wikipedia editors use for sourcing. Maintain the same name, description, and category across every external listing, because ChatGPT does entity resolution and inconsistent metadata reduces citation confidence.
02
For Perplexity: be recent and specific
Perplexity rewards freshness and concrete data. The most direct lever is publishing date-stamped pages with specific numbers, methodology, and named sources, and updating them at least quarterly. Visible "2026" date signals in titles and URLs increase citation rates by about 30%. Reddit presence helps because Perplexity cites Reddit heavily; this does not mean posting promotional content, it means contributing genuine answers in relevant subreddits over time. For small businesses, a single well-researched Reddit answer that gets upvoted in r/SEO or r/SmallBusiness can produce more Perplexity exposure than a month of blog posts.
03
For Claude: write long-form explainers
Claude rewards depth. Short news briefs and listicles compete poorly here. The pages that win Claude citations tend to be 2000-5000 word explainers that walk through a concept in detail, include reasoning rather than just claims, and structure their content so individual sections are self-contained. Documentation pages, technical guides, and analytical pieces that explain "why" rather than just "what" perform best. Claude visitors also convert at the highest rate of any AI traffic source (about 16.8%), so even a small citation share can produce meaningful pipeline. The full process for writing long-form articles that match this pattern, including two ready-to-copy prompts, is in how to write SEO content with AI that gets traffic without sounding like a robot.
04
For Google AI: add structured signals and video
Google AI is the most signal-driven of the four engines. The levers are well-known but underused: comprehensive schema markup (Article, FAQPage, HowTo, BreadcrumbList where applicable), direct-answer formatting in the first 40-60 words of each section, statistics with source citations every 150-200 words, and YouTube video versions of core topics. A single tutorial video with a clear transcript can earn citations a text page on the same topic cannot. The GEO playbook covers the schema and structure details, and the tracking guide shows how to measure progress without a dedicated platform.
Methodology and sources
These numbers come from public benchmarks published in 2026, combined with my own small-scale testing on IvaBot's traffic and a handful of client sites I have worked with. The patterns are consistent across both: AI engines cite different sources for the same query, and what works for Google AI Overviews often does not translate to ChatGPT or Perplexity. Do not take this as agency-grade data, take it as a starting point you can verify yourself by running the same queries across engines.
Primary sources referenced in this article:
Averi 2026, B2B SaaS Citation Benchmarks Report, analysis of 680 million citations across ChatGPT, Google AI Overviews, and Perplexity
Passionfruit 2026, analysis of 15,000 queries across three platforms
Slate HQ 2026, 300,000+ citation analysis across six B2B SaaS brands
Moz 2026, analysis of 40,000 keywords for AI Mode citation overlap with organic top 10
Ahrefs 2026, AEO benchmarks from 863,000 keywords and 4 million AI Overview URLs
Semrush 2026, AI & SEO Report on citation overlap and brand disagreement
Peec AI 2026, 30 million source analysis on most-cited domains
ClickGuard 2025, research on Google AI Overview source breakdown by domain
The Digital Bloom 2026, brand mention correlation with AI citations
Conductor 2026, AEO/GEO Benchmarks on AI referral traffic
Seer Interactive 2025-2026, on conversion rates for AI-referred traffic
Superprompt 2025, on schema markup and original data citation lift
FAQ
Where does ChatGPT get its information from?
ChatGPT gets its information from two sources: its training data, which is a fixed snapshot of text from books, articles, websites, and Wikipedia up to its training cutoff, and live web search through Bing for queries that require current information. The exact mix depends on the model variant and whether browsing is enabled in the session.
Does ChatGPT get information from the internet?
Sometimes. ChatGPT uses live web browsing (through Bing) for queries that require current information, but answers from its training snapshot for general knowledge questions. The same prompt can hit either path depending on the model and whether real-time data is needed.
Does ChatGPT cite Wikipedia?
Yes. Wikipedia accounts for about 47.9% of ChatGPT's top citation positions in 2026 benchmarks. It is consistently the primary source for definitional and historical questions, and ChatGPT was trained heavily on Wikipedia content during its foundation training.
Does Perplexity use Reddit?
Yes, heavily. Reddit accounts for about 46.7% of Perplexity's top citation positions in 2026. It is the single highest source category for the engine. Perplexity pulls from Reddit because community threads contain experiential answers and recent discussions that match its query intent for opinion and recommendation-style questions.
Where does Google AI Overview get its information?
Google AI Overviews pull from Google's own search index, the Knowledge Graph, and structured user-generated content from forums and review platforms. The top citation sources in 2026 are YouTube (23.3%), Reddit (21%), Quora (14.3%), LinkedIn (13%), and Wikipedia and Forbes (around 5.7% each). About 38% of AI Overview citations come from pages in the top 10 organic results.
Where does Google AI get its information?
Google AI gets its information from Google's own search index combined with the Knowledge Graph. This applies to both Google AI Overviews (the block above organic results) and Google AI Mode (the standalone chat interface). The retrieval pipeline runs the query through Google's index, scores candidate pages, and synthesizes citations into a structured answer. Top-cited domain categories in 2026 are YouTube, Reddit, Quora, and LinkedIn.
Where does Claude get its information?
Claude uses Anthropic's training data for general knowledge and Brave Search for real-time web retrieval. Its top citation category is long-form blogs and articles (about 43.8% of citations), which makes it the most depth-favoring of the major AI engines.
Do AI engines cite the same sources?
No. Only about 11% of domains are cited by both ChatGPT and Perplexity for the same query, according to Averi's 2026 analysis of 680 million citations. Passionfruit found 12% overlap across three platforms. The lists barely overlap because each engine uses a different web index, retrieval pipeline, and source preference.
How does ChatGPT choose its sources?
ChatGPT chooses sources based on a combination of training data weighting (which favors authoritative reference sites like Wikipedia), real-time Bing retrieval for current queries, and structural signals like schema markup and consistent entity metadata. The exact selection logic varies by model variant. The default model and premium models can return different citation sets for the same prompt.
What's Next
If you want to act on this, the practical next step is to test your own site against all four engines, not just one. Run a small set of buyer-relevant queries through ChatGPT, Perplexity, Claude, and Google AI Mode, and note which engines cite your domain and which do not. The gaps will tell you where to spend the next month of content work.
This article was drafted using IvaBot Content Builder, with citation data from public 2026 benchmarks and IvaBot's own DataForSEO integration. The Reddit comment that prompted it is real, the data sources are linked above, and the recommendations are what I would tell a friend running a small business site asking where to start.
 15 min read
15 min read